
En esta entrada, haremos una breve (brevísima) introducción a la clase Series de Pandas. Es la estructura más simple que proporciona Pandas, y se asemeja a una columna en una hoja de cálculo de Excel.
Un objeto Series tiene dos componentes principales: un índice y un vector de datos. Ambos componentes son listas con la misma longitud. El índice contiene valores únicos y, por lo general, ordenados, y se usa para acceder a valores individuales de los datos.
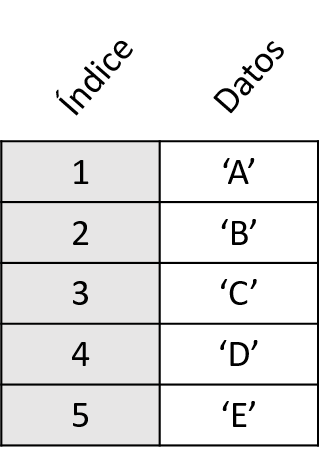
Esquema de un objeto Series
Para crear un objeto Series, se debe llamar al constructor:
>>> import pandas as pd >>> idx = range(4) >>> vals = ['a','b','c','d','e'] >>> s = pd.Series(index=idx, data=vals) >>> print(s[1]) b
En este ejemplo se ha creado un objeto Series que contiene caracteres indexados por números enteros (obtenidos mediante la llamada a range()), aunque los papeles podrían invertirse. Un objeto Series puede usarse también para representar una función matemática:
>>> import numpy as np >>> x = np.arange(-10,10,1) # Crear un rango de -10 a 9 contando uno a uno >>> s = pd.Series(index=x, data=x**2) # x**2 devuelve el valor de cada elemento de x elevado al cuadrado >>> print(s) -10 100 -9 81 -8 64 -7 49 -6 36 -5 25 -4 16 -3 9 -2 4 -1 1 0 0 1 1 2 4 3 9 4 16 5 25 6 36 7 49 8 64 9 81 dtype: int32
En este ejemplo se ha incluido la librería Numpy, limitándolo a un uso muy simple. Es una librería muy interesante para programación científica o análisis de datos. Se puede acceder a los elementos individuales o bien a un rango de los mismos en el vector indexado usando el método Series.loc[]:
>>> s.loc[6] 36 >>> s.loc[-3:3] -3 9 -2 4 -1 1 0 0 1 1 2 4 3 9 dtype: int32
Hay muchas otras formas de acceder a los datos, pero por simplicidad, aquí sólo veremos Series.loc[] por cuestiones de simplicidad. En la documentación se puede ver el resto de los métodos.
Y ahora, vayamos a la parte divertida. Los datos pueden seleccionarse usando indexado condicional para seleccionar valores que cumplan unas condiciones dadas:
>>> sMayor64 = s.loc[s>50] >>> print(sMayor64) -10 100 -9 81 -8 64 8 64 9 81 dtype: int32
Además de seeccionarlos, podemos ver sobre los datos originales cuáles son los que cumplen los criterios:
>>> s>50 -10 True -9 True -8 True -7 False -6 False -5 False -4 False -3 False -2 False -1 False 0 False 1 False 2 False 3 False 4 False 5 False 6 False 7 False 8 True 9 True dtype: bool
Finalmente, veremos cómo aplicar una función sobre un objeto Series elemento a elemento. Esta funcionalidad es muy importante en análisis de datos, y se podría dedicar una entrada completa a este tema. En primer lugar, necesitamos tener una función que aplicar sobre los elementos. Para ello, las funciones lambda pueden resultar muy útiles, pero por simplicidad, usaremos una función predefinida, numpy.sqrt(), que sirve para obtener la raíz cuadrada, incluída en la librería Numpy:
>>> s2 = s.apply(np.sqrt) >>> print(s2) -10 10 -9 9 -8 8 -7 7 -6 6 -5 5 -4 4 -3 3 -2 2 -1 1 0 0 1 1 2 2 3 3 4 4 5 5 6 6 7 7 8 8 9 9 dtype: float64
El método Series.apply() toma la función que se pasa como parámetro (en este caso numpy.sqrt()) y la aplica elemento a elemento; y devuelve un nuevo objeto Series que tiene un índice idéntico al original.
En la siguiente entrada, veremos la clase DataFrames. Por supuesto, esto es una introducción muy superficial, basada en mi uso habitual. Hay más material de lectura acerca de la clase Series el tutorial de Pandas y la documentación oficial.